最近,作陪着DeepSeek的火爆,「模子蒸馏」这个专科名词,也当年出当今民众视线。
什么是模子蒸馏呢?
“模子蒸馏”等于把大模子学到的智商,用“浓缩”的神气教给小模子的经过,在保证一定精度的同期,大幅缩短运算老本和硬件条目。

大模子:像一位博物洽闻、学问储备远大的“大教训”,无所不知,然则“服侍”他很贵。
不仅培养他的经过很耗时耗力(捕快老本高),请他过来授课老本也很高,要有很大一笔安家费(部署模子的硬件基础设施,致使数据中心),还要支付超高的课时费(推理老本高)。

小模子:终点于一枚小学生,学问面相配有限,然则胜在没教训那么大谱,给个板凳坐着就够了(部署老本低,推理老本低)。

小模子想要领有跟大模子全王人同样的才能是不试验的,毕竟一分钱一分货。
然则咱们可以让大模子教小模子一些基本的解题念念路,让学生和本分同样念念考问题。
教训会100种解题念念路,挑两三种可以的教给小学生,让小学生轻重缓急。
这个解题念念路滚动的经过,其实等于模子蒸馏。

以DeepSeek发布的六个蒸馏模子为例,满血版671B参数目的DeepSeek R1等于“教训模子”。
而教训模子针对不同尺寸的学生模子进行学问蒸馏,这些学生模子包括↓
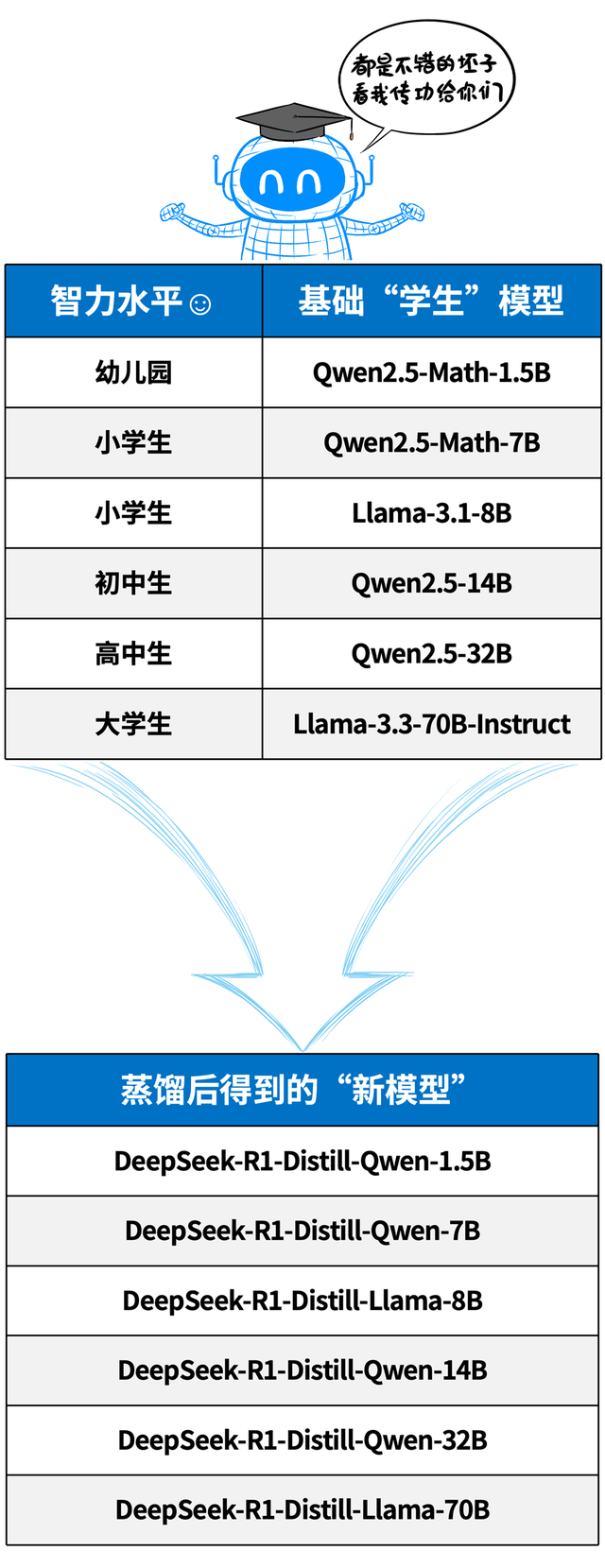
看,前几天让全球土产货装置的那些模子,其实等于从DeepSeek R1这个本分蒸馏得到的,每个学生王人从本分身上学到了些“三脚猫”功夫。
因为学生模子的运行禀赋不同,是以得到的蒸馏模子才能也不同。
总之,脑容量越大(权重数/参数目),才能就越强,就越接近本分的水平。

那么,模子蒸馏具体是奈何干的呢?
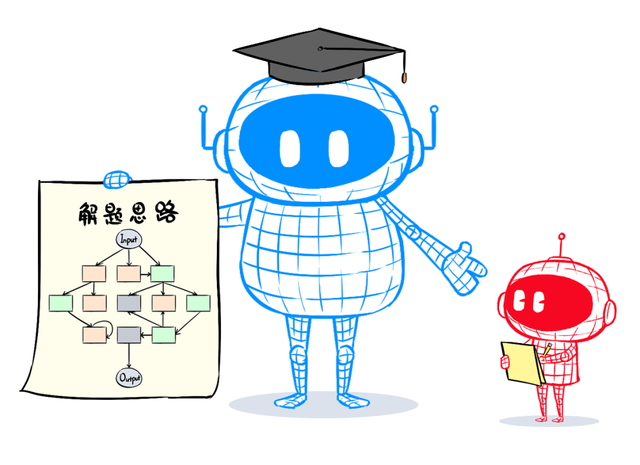
简便说,等于本分作念一遍,学生随着学。
但针对每个输入的问题,本分不会凯旋给出详情谜底,而是给出解题念念路(俗称软标签)。
比如,输入一张猫的像片给本分模子,本分不会凯旋给出谜底:这是猫,而是给出一组概率散播,告诉学生,这张图可能是什么。
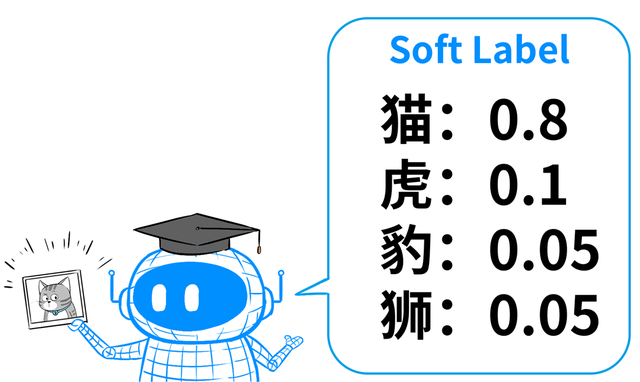
本分这样干,等于为了让学生具备举一反三、通今博古的才能,用概率散播来对应多样类别的相似进度。
若是只告诉学生这是猫,学生就不知说念它和老虎有若干离别。通过这种有概率散播的软标签,学生就知说念了本分是怎样判断、怎样分歧。

接下来,需要建树小模子的学习尺度(轮廓亏欠函数)。
本分天然NB,但小模子在学习的期间,并不会全王人照搬本分的念念路。
它会攀附我方原特地据汇聚的硬标签(猫等于猫、狗等于狗),再参考本分的谜底,最终给出我方的判断。
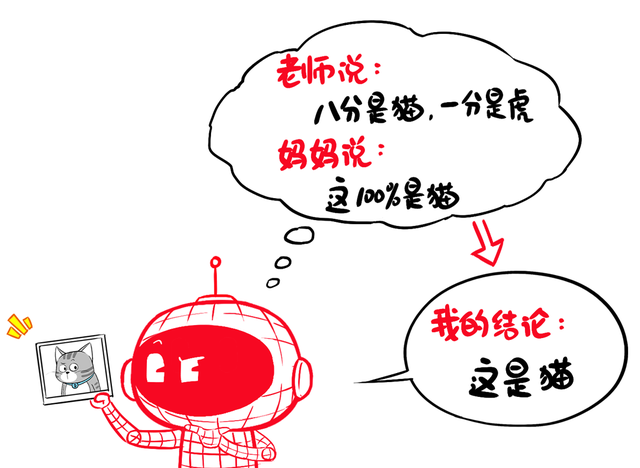
是以,学生模子既要参考“教训给的学习札记”(软标签),又要攀附“姆妈给的判断”(原有监督学习中的硬标签)。
实操中,用“蒸馏亏欠”来猜测学生模子与教训模子输出戒指的各别。用“信得过监督亏欠”来猜测学生模子对基本黑白问题的判断。
然后,再设定一个均衡统统(α)来改动这两种亏欠,达到一个最优遵循。
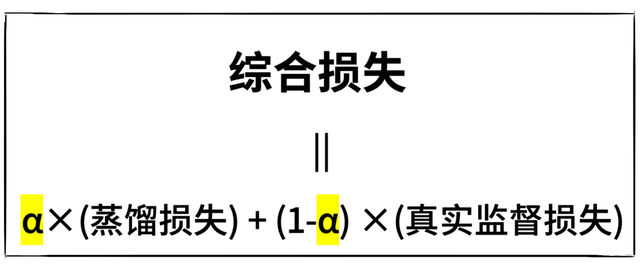
说白了,学生模子要尽量效法教训模子的行动,蒸馏亏欠越小越好,然则又不可学傻了,基本的黑白问题王人答分歧。

尺度详情后,就可以插足厚爱的蒸馏捕快了。
❶把吞并批捕快样天职别输入到学生模子和教训模子;
❷凭据硬标签和软标签,对比戒指,攀附权重,得到学生模子最终的亏欠值;
❸对学生模子进行参数更新,以得到更小的亏欠值。
束缚类似这个经过❶→❷→❸,就终点于反复刷题,每刷一轮,就找找学生谜底和本分谜底的差距,实时修订。
经过多轮以后,学生的学问就会越来越塌实。
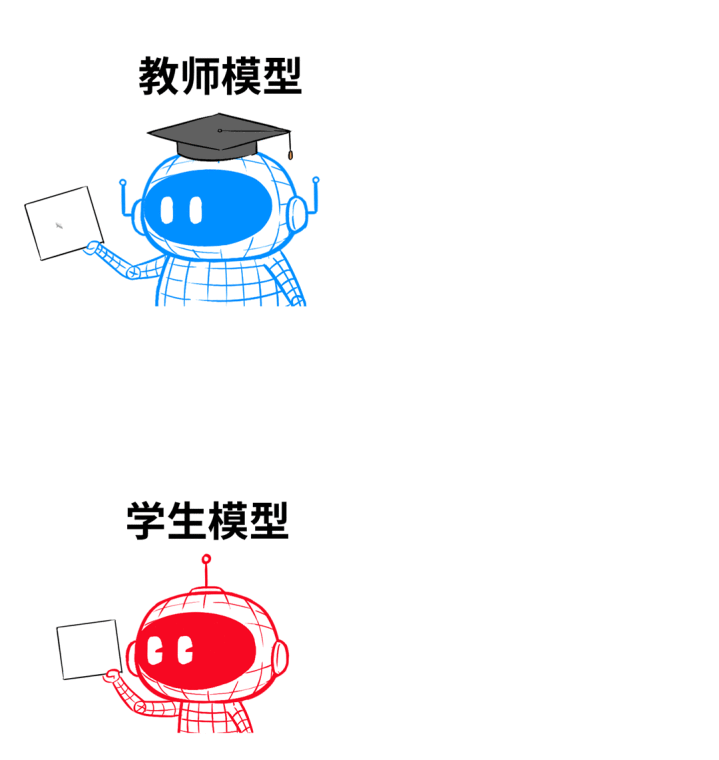
最终,蒸馏得到的小模子,尽量复制大模子的灵巧,同期保抓我方身轻如燕的上风。
这样,学生模子就可以看成课代表,孤独带班,不需要教训镇守了。

推广阅读
一、对于不同的蒸馏道路
前边讲的这种模子蒸馏,仅仅最常见、最通用的一种神气,叫作念学问蒸馏,也叫输出层蒸馏。
终点于本分凯旋告诉你终末的谜底,学生只需要抄功课,效法本分的谜底就行。
这种神气操作起来最简便,即便西席模子不开源,你拿不到西席模子,唯有能调用他的API,看到本分的学问输出,就可以效法他,蒸馏出我方的小模子。
是以,有些模子比如GPT4,是明确声明不允许学问蒸馏的,但唯有你能被调用,ag百家乐就没法幸免别东说念主偷师。
坊间传说,业界大模子厂商之间,王人存在彼此蒸馏的操作,正所谓“彼此效法、共同跨越”。

除了输出层蒸馏,还有中间层蒸馏(也叫特征层蒸馏),不仅学到最终判断的论断,还学习本分对图像/文本的里面领会,更深切地收受本分的“学问结构”。
终点于学生不光看本分的最终谜底,还要看本分的解题经过或中间体式,从而更全面地学到念念考次序。
但这种蒸馏决策,操作难度较高,当年需要西席模子允许,致使主动配合,适用定制化的技俩相助。
不外当今也可以通过一些技艺来获取西席模子的推理轨迹(Reasoning Traces),比如使用特殊构造的教导词来指点本分逐渐复返推理,得到推理轨迹。
同期随着多样推理模子的推出,有些推理模子的API本人就救济复返推理轨迹,比如Google Gemini2.0 Flash,DeepSeek等等。
二、对于蒸馏、微妥洽RAG
这三种次序,王人是优化的大模子的技艺,然则已毕旅途和运用场景不同。
蒸馏:是学生通过效法本分的解题念念路,达到和本分相似的学问水平。
适用于将大模子的才能迁徙到小模子上,以适配更低端的算力环境。(比如在企业独特云、个东说念主电脑致使手机、旯旮结尾上)

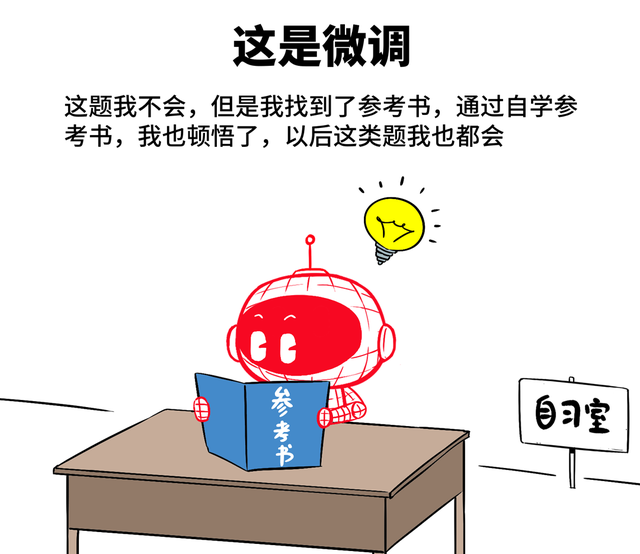
微调:又叫精调,终点于学生瓦解到我方某门课有短板,然后我方找参考书恶补了一下,从而补上短板。
适用于特定场景下,用特定数据集对通用模子进行小限制捕快。比如通用基础模子对医疗不大懂,就用医疗数据集给它开小灶,让他变身医疗行家模子。
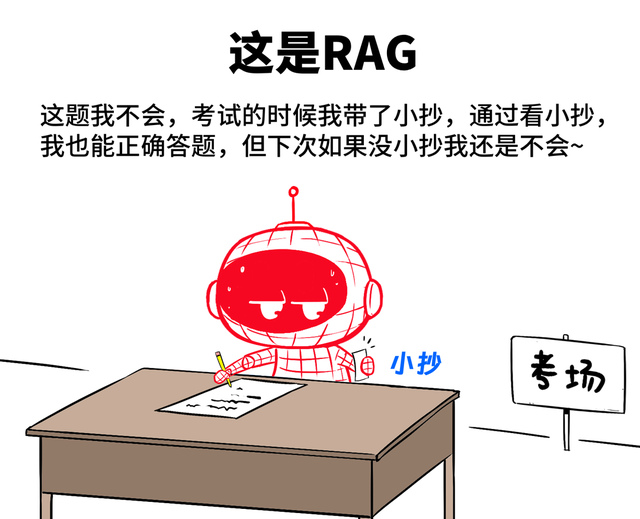
RAG:直译过来叫作念“检索增强生成”。终点于这题我不会,然则我有“小抄”,我回答的期间,就看一眼小抄,然后再轮廓我脑子里的已有学问,进行回答。
RAG,不是捕快,不改变大模子的“脑回路”,但可以看成外挂,教训大模子回答问题的精确性。适用于企业自身麇集了遍及学问库文档,通过RAG的神气,与大模子关系。
这样,大模子在回答问题的期间,会先检索学问库,进行精确回答。
三、举两个试验的例子
举个例子,当今特大号公众号后台的自动呈文,其实等于腾讯混元大模子,通过RAG的神气,攀附了特大号通盘的历史著作,看成学问库使用。
当你发问的期间,它就会检索这些历史著作,然后再回答问题。
再举个例子,前几天被热传的李飞飞团队仅破耗50好意思元,就捕快出一个并排ChatGPT o1和DeepSeek R1的模子,其实是一种误读。
李飞飞团队的s1模子,其实是基于通义的开源模子Qwen2.5-32B进行的微调,而微调所用的数据集,其中一部分蒸馏自Google Gemini 2.0 Flash Thinking。
是以,这个模子的降生,是先通过学问蒸馏,从Gemini API获取推理轨迹和谜底,赞助筛选出1000个高质料的数据样本。
然后,再用这个数据集,对通义Qwen2.5-32B进行微调,最终得到性能证实可以的s1模子。
这个微调经过,迫害了50好意思元的算力用度,但这背后,却是Gemini和Qwen两大模子无法估量的隐造老本。
这就好比,你“偷了”一位名师解题念念路,给了一个学霸看,学霸底本就很NB,当今看完“念念路”,变得更NB了。
严格来讲,Gemini 2.0看成闭源生意模子,天然救济获取推理轨迹,但原则上是不允许用作蒸馏的,即便蒸馏出来也不可商用。不外若是仅是发发论文、作念作念学术计划、博博眼球,倒也无可厚非。
天然,不得不说,李的团队为咱们绽放了一种念念路:咱们可以站在巨东说念主的肩膀上,用四两拨千斤的次序,去作念一些创新。
比如,DeepSeek是MIT开源授权,代码和权重全开放,况兼允许蒸馏(且救济获取推理轨迹)。
那么对于好多中小企业来讲,无异于巨大福利,全球可以松驰通过蒸馏和微调,获取我方的专属模子,还能商用。
GenAI的普惠改动期间,惟恐的确来了。
 ag百家乐
ag百家乐